
Blog
AI-Powered Root Cause Analysis for Test Failures

Published on
May 30, 2026


Discover how AI-powered root cause analysis transforms test failures into instant insights. Learn how QA teams cut debugging time and accelerate releases.
The most expensive minute in software testing is not the one spent running a test. It is the one spent figuring out why a test failed.
Multiply that minute by every failure across every run. Then multiply it again by the speed at which AI tools now generate code, and the arithmetic breaks. The bottleneck in modern QA is not test execution. It is test triage.
AI-powered root cause analysis exists to fix that bottleneck. When a test fails, the system reads everything it can about the failure: the logs, the screenshots, the recent code changes, the history of similar failures. It produces a structured answer to the question every engineer asks first: why.
This guide covers what AI-powered RCA actually does, the five failure classes any serious system must distinguish, how the technology works, the confidence ladder that separates a real RCA system from a marketing claim, what it genuinely solves, what it does not, and how to measure whether it is working.
AI-powered root cause analysis is the use of AI to classify a failing test, identify the most likely cause, and present the supporting evidence to a human reviewer in minutes rather than hours.
The system reads logs, screenshots, code changes, and the history of similar failures, then narrows thousands of possible explanations to the small handful that matter.
The job AI-powered RCA is hired to do is straightforward: eliminate the time between a test failing and the team knowing why.
When a nightly suite produces ninety failures, the team faces ninety triage decisions. Each one used to consume between fifteen minutes and an hour of engineer time. Across a single failed run, that adds up to most of a working day spent not writing tests, not improving coverage, and not building features.
AI RCA collapses that time by making three structured contributions to every failure.
Genuine application defect, test drift, test logic bug, environment issue, or flake. The classification alone tells the team where to look and who should look there.
The specific test step, the specific code change, the specific UI element, the specific service. The investigation narrows from the whole codebase to one small region.
Screenshots, video, console output, network traces, the diff of the recent code change, the history of similar failures. The reviewer reads, decides, and moves on.
The reviewer does not stop being part of the process. The reviewer stops being the entire process.
AI tools now write a meaningful share of new enterprise code. Code generation velocity has increased significantly. Refactor frequency has increased. Failure volume has increased because every change is a potential failure trigger.
Triage capacity has not increased at the same rate. QA teams have not grown at AI velocity. The mismatch shows up as triage backlogs, false-failure noise that erodes trust, and the gradual normalisation of what is arguably the worst metric in QA: the green failure. A failure that everyone agrees does not matter and nobody investigates.
The trust problem compounds. When the team learns to ignore noisy failures, real failures buried in the noise get missed too. The suite becomes background activity rather than a working signal.
AI root cause analysis is the structural answer. A platform that reduces average triage time from forty minutes to four does not just save ninety percent of the cost. It converts the QA function from a constraint into an enabler.
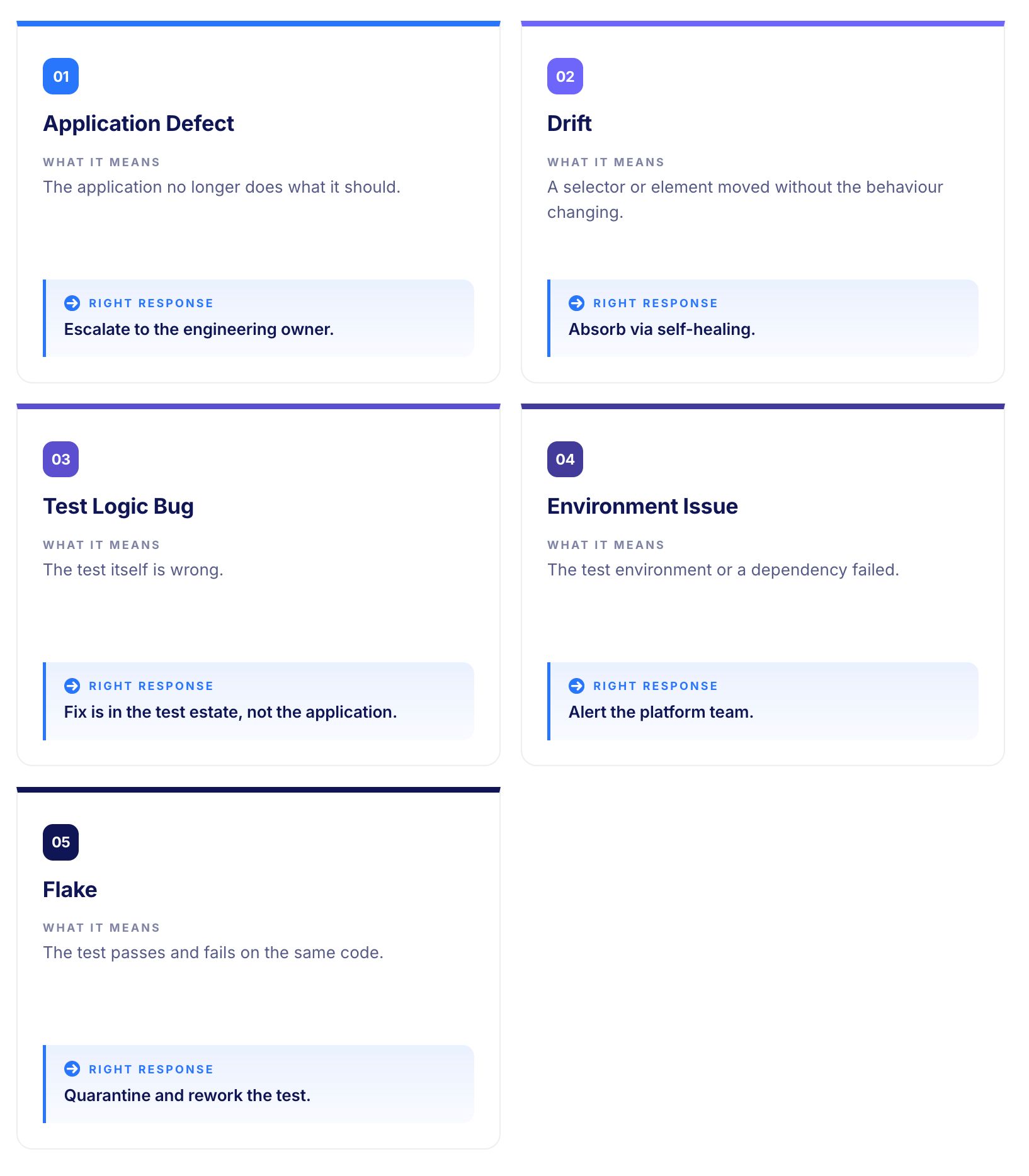
The application no longer does what it is supposed to do. The test caught a real regression. The failure reproduces on every run against the same application state. The screenshot or video shows the application behaving differently from what the test expected. The recent code changes touched a region the test exercises.
A good AI root cause analysis system flags Class 1 failures with high confidence and routes them directly to the engineering owner. This is the class every test suite exists to find.
The application has changed in a non-functional way. A selector moved, a structural attribute changed, a label was renamed. The user experience has not changed. The defect, if there is one, is in the test's anchors, not in the application.
Self-healing platforms absorb most drift automatically. A mature AI root cause analysis system suppresses these failures or surfaces them as informational rather than escalating them as defects.
The test itself is wrong. A boundary value that was correct in the original specification is no longer correct after a business rule changed. An assertion that compared the wrong fields. A setup step that depends on stale data.
The application behaviour matches what the application should do. The test expectation matches what the application used to do, or what the author thought it should do. The fix is in the test estate, not the application.
The test failed for reasons unrelated to the application or the test. The environment was unreachable. A dependent service was down. A certificate had expired. The CI runner ran out of disk space.
The same test passes when re-run on a healthy environment. Failures in this class should not feed the engineering backlog. They should feed the platform team's reliability work.
The test sometimes passes and sometimes fails on the same code, the same data, and the same environment. The cause is non-deterministic: a race condition in asynchronous code, a timing-sensitive assertion, an animation that completes at variable speed.
Re-running the test changes the outcome. The right response is not to fix the failure but to quarantine the test and rework it properly.
A serious AI root cause analysis system distinguishes all five classes and routes each to a different response. A weak system flags everything as failure and leaves the human to do the classification work. The difference is the entire value of the capability.

Six techniques contribute to the structured answer the reviewer receives. Most platforms use a combination rather than any single one.
The system reads test execution logs, application logs, network traces, and infrastructure traces in real time. Patterns that experienced engineers recognise after years of practice, a particular timeout signature, a specific exception class, a memory pressure indicator, are detected automatically.
Large language models trained on observability data convert verbose, semi-structured logs into a one-line diagnosis.
The system maps the failure to the recent code changes most likely to have caused it. The repository commit history, the file paths touched, the modules involved in the failing step, and the historical correlation between changes in those modules and similar failures all feed the ranking.
A failure that maps to one specific commit with high confidence turns triage into a review of one change rather than a hunt across the codebase.
For UI failures, the system compares screenshots from passing runs to the screenshot at the moment of failure and highlights the regions that differ. A missing button, a moved field, an unexpected modal, a content shift.
The visual diff is often the fastest path to a Class 1 diagnosis when the failure is in the interface itself.
The system compares the current failure to the history of failures across the team, the project, and the organisation. Failures with similar logs, similar stack traces, or similar visual signatures cluster together.
A failure that matches a known cluster inherits the cluster's diagnosis and resolution history. Knowledge from previous investigations reaches new failures without manual transfer.
For platforms with deep integration into source control, the system traces the failing test step to the application code it exercises and reports the changes to that code since the last passing run. The reviewer sees the test, the failed step, the relevant code, and the diff in a single view. The leap from what failed to why it failed collapses.
A modern AI RCA system uses a large language model to turn the structured evidence into a plain-language explanation. The explanation reads like an experienced engineer's hypothesis: the test failed because the recent change to the order-confirmation page renamed the submit element and the test's anchor no longer matches the new label.
The reviewer evaluates the hypothesis rather than constructing it from scratch.
Not every AI RCA system performs at the same depth. Five levels define how analytical depth increases from basic classification to autonomous remediation.
The ladder is a useful frame for evaluating platforms and for setting realistic expectations within a team.

The system identifies which of the five failure classes the failure belongs to and presents the classification with a confidence score. Even at this level the gain is significant. Routing failures correctly to the right response path is most of the triage problem.
The system names the most likely cause in plain language.
Not just "Class 1: application defect" but "the submit button on the checkout form is no longer responding to the click event after the recent refactor of the cart component." The reviewer gets a hypothesis to evaluate rather than a label to act on.
The system identifies the specific commit, file, or configuration change most likely responsible. The reviewer goes from a region of suspicion to a single line of suspicion. Triage time collapses from minutes to seconds. Most credible platforms operate at this level in production today.
The system proposes a fix drawn from prior resolutions of similar failures or generated from the change context. A renamed selector, an updated assertion, a rewritten timing wait. The reviewer evaluates and applies the fix. The system did the design work.
The system applies the fix on its own when confidence is sufficient, with full audit logging and human-reversible governance. The remediation is logged, reviewable, and revertible. The team receives a stream of fixes rather than a queue of failures to investigate.
The honest position for vendors in this space is Level 3 at production-grade confidence today, Level 4 in active development, and Level 5 emerging only in narrow, well-bounded contexts, most often self-healing of element selectors with a known structural mapping. Any vendor claiming reliable autonomous remediation across all five failure classes is overclaiming. The cost of getting Level 5 wrong is the silent modification of working tests and the masking of real defects.
Average time from failure to diagnosis drops from tens of minutes to single-digit minutes. Multiplied across a year and across a large test suite, the saving is one of the largest productivity recoveries available to a modern engineering organisation.
When drift, environment issues, and flake are classified and suppressed automatically, the remaining failures are the ones that matter. The signal-to-noise ratio of the suite rises, and the team's trust in the suite rises with it.
Senior engineers carry the diagnostic experience that lets them triage failures quickly. AI RCA externalises that experience, makes it available to everyone, and raises the team's average capability without depending on individual seniority.
A failure that has occurred before anywhere in the organisation no longer needs to be re-investigated from scratch. Similar-failure clustering surfaces the prior resolution and the new failure inherits it.
Failures that arrive overnight are classified and routed before the on-call engineer needs to act. Environment issues go to the platform team. Genuine defects go to the engineering owner. Flake gets quarantined. The on-call shift becomes proportionate to the genuine work.
Every diagnosis is logged: what the system concluded, with what confidence, on what evidence, leading to what action. The audit trail is produced as a side effect of the work rather than as a separate compliance project.
A guide that is honest about limits is a guide worth citing.
A failure triggered by a third-party service whose internals the platform cannot see is a failure the system can describe but not explain. The team still has to make the call to the vendor.
A failure whose true cause is a misunderstanding of a business rule across multiple components requires human reasoning the AI cannot reliably reproduce. The system can present the evidence. The team has to argue the case.
A badly designed test produces failures whose cause is the design, not the application. AI RCA may correctly classify it as a Class 3 failure but cannot redesign the test. Good test design discipline remains essential regardless of the RCA tooling.
AI RCA operates on the data it is given. A team with poor logging, missing traces, or unreliable timestamps produces a triage pipeline that no AI can fix. Good observability is the prerequisite, not the deliverable.
The system can classify a failure as a genuine defect. Whether that defect blocks a release, requires a hotfix, or can be deferred is a business decision the team owns. The AI gives the evidence. The team gives the verdict.

Six metrics together turn the AI RCA investment from an anecdote into a measurable discipline.
The elapsed time between a test failure being recorded and a human-actionable diagnosis being produced. The pre-AI baseline for most teams sits between fifteen and sixty minutes per failure. Mature AI RCA platforms reduce the median to single-digit minutes. This is the headline metric.
The percentage of failures the system classifies correctly into the five-class taxonomy. Healthy systems sit above ninety percent on the first three classes (defect, drift, test bug) and somewhat lower on the harder distinctions between environment failures and flake. Track accuracy by class, not only in aggregate.
The estimated engineering hours per cycle returned to other work because AI RCA short-circuited the investigation. A conservative estimate draws a per-failure delta between the pre-AI baseline and the post-AI median, then multiplies by failure volume. The number is typically large enough to fund the platform investment several times over.
The percentage of failures correctly suppressed or de-escalated by the AI (drift, environment, flake) before reaching a human reviewer. A healthy suppression rate increases the value of the failures that do reach reviewers, because each one is more likely to be a Class 1 defect.
For platforms operating at Level 4 or above, the percentage of suggested fixes the team accepts on review. Acceptance below seventy-five percent indicates the system is over-eager and needs tuning. Acceptance above ninety-five percent is healthy.
The elapsed time between failure detection and a verified fix in the application or test estate. Mean time to fix is the compound metric that AI RCA most directly influences and the one engineering leadership is most likely to recognise as meaningful.
Turning on the capability is not the same as getting the value from it. Five practices separate the teams that recover the hours from the teams that buy the licence and stay where they were.
The first benefit, correctly routing failures into the five classes, is the largest, the easiest to validate, and the foundation everything else builds on. Prove the classifier on a focused subset of suites before extending into deeper analysis.
The five-class framework is the baseline. Most teams add one or two organisation-specific classes: a known integration partner whose failures are their own category, a compliance-driven failure that needs separate routing. The system improves rapidly when the taxonomy reflects the team's actual failure landscape.
Every flake quarantine, every self-heal, every classification should be reviewable. A weekly review of automated actions catches drift in the system's behaviour before it becomes a quality problem in its own right.
Every failure the team resolves manually should feed back into the system's pattern memory. Modern platforms automate this. The discipline is to keep the feedback loop healthy and to retire stale patterns when underlying systems change.
Without measurement, the question of whether AI RCA is working devolves into opinion. The six metrics above provide the numbers worth tracking from the first week of adoption.
When a test fails in Virtuoso QA, the platform does not ask the engineer to start the investigation from nothing.
AI Root Cause Analysis reads the test steps, network events, failure reasons, error codes, and UI comparisons together and produces a structured diagnosis. The engineer receives a classified failure, a likely cause in plain language, and the evidence that supports it: logs, screenshots, and network traces in a single view.
Self-healing handles Class 2 drift failures automatically. When a selector changes or an element moves, Virtuoso adapts the test and logs the change for review. The team is not woken up for a failure that was never a defect.
Composable test libraries mean that when a shared module fails, the diagnosis traces directly to the module and the journeys that use it. The blast radius of a broken change is visible immediately rather than discovered one failed test at a time.
End-to-end journey tests run continuously and feed every failure through the same classification pipeline. Regression failures surface as classified defects, not as a list of red lines on a dashboard that the team has to make sense of manually.
The combined effect is a triage function that scales with code velocity rather than against it.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.